데이터 분석의 기초 (1) 데이터 분석 개요 - 한국데이터베이스진흥원
데이터의 시대 Datafication
분석이란 무엇인가?
결정을 내리고 행동에 옮기기 위해 데이터, 통계 분석과 계량 분석, 설명 모델과 예측모델 등을 폭넓게 활용하는 것
빅데이터 시대의 통계적 사고
기술의 융합, 측정의 혁명적 변화, 미래의 의사결정에 관한 관점 혹은 철학 -Steve Lohr, NYT
모집단과 표본
빅데이터 시대에도 모집단과 표본이라는 개념이 필요한가?
우리가 모든 데이터를 가지고 있다면 왜 표본을 추출해야하는가?
표본 추출은 분석의 난제를 일부 해결한다.
편의(bias)
데이터로부터 발견한 어떠한 추론도 해당 사용자 집단 또는 어떤 특정한 날의 사용자들 이외의 다른 사람들에 대한 일반화된 결론으로 확대하는 것을 경계
표본추출
표본추출
통계학에서는 모집단과 표본의 관계를 수학적으로 모형화
이 모형화를 통해 데이터가 생성되는 발생 과정, 수학적 구조, 형태에 대한 단순화된 가정들
그 발생과정에서 특정 한 것(사건, 현상, 상태 등)들을 관찰이 표본이다.
통계적 추론 (통계적추정량 statistical estimators)
데이터분석가에 의해 달라지짐
무작위성(randomness)
불확실성(uncertainty)
통계학(Statistic)이란?
자료로 부터 유용한 정보를 이끌어내는 학문
추출단위(Sampling unit): 모집단을 구성하는 각 개체
특성값(Characteristic values): 각 추출 단위의 특성을 나타내는 값
모집단(population): 통계적 분석의 대상이되는 조사 대상 전부
표본(sample): 통계적 분석을 위하여 선택된 모집단의 일부
표본 추출법
1) 단순 랜덤 추출법(Simple random sampling)
모집단의 각 추출단위가 표본으로 선택될 확률이 같은 방법
- 단순 랜덤 비복원 추출(simple random sampling without replacement): 동일 개체 중복 추출 불가
- 단순 랜덤 복원 추출(simple random sampling without replacement): 동일 개체 중복 선택 가능
2) 층화 추출법(Stratified sampling)
모집단을 몇개의 동질적인 층으로 나눈다음, 각 층에서 표본을 단순랜덤추출
3) 집락 추출법(Cluster sampling)
추출단위: cluster <- 추출작업이 편리하고 비용절감
4) 계통 추출법(Systematic samplig)
모집단의 원소들에게 번호를 부여하고, 순서대로 나열한 후, K(=N/n)개씩 n개의 구간으로 나눈다.
각 구간에서 하나를 임의 선택하여 K개의 표본을 추출
표본 조사시 유의점
1. 정확한 리스트 작성
2. 무응답 오차
3. 응답오차
4. 유도질문
자료의 종류
자료의 종류
1. 질적 자료(Qualitative data)
1) 명목 척도(nominal scale): 집단관계
ex) 남/여
2) 순서 척도(ordinal scale): 서열관계
ex) 아주 좋아한다/ 좋아한다/그저그렇다
2. 양적 자료(Quantitative data)
1) 구간 척도(interval scale): 속성의 양 측정(두 관측값 사이의 비율은 별 의미 없음)
ex) 온도, 지수
2) 비율 척도(ratio scale): 절대적 기준인 0값이 존재하고 모든 사칙연산이 가능하며, 제일 많은 정보를 가지고 있는 척도
ex) 무게, 나이, 연간소득 등 숫자로 표현되는 일반적인 자료
위치 측도(location parameters): 특성값들의 대략적인 크기를 나타내는 측도
1) 표본평균(smaple mean): 데이터의 합계를 데이터의 총 개수로 나눈값
2) 중앙값(median): 데이터의 크기를 순서로 나열할 때, 가장 중앙에 위치하게 되는 데이터 값
3) 분위수(quantile): q-quantiles, 정렬된 데이터를 균등하게 q개로 나누는 값들
4분위수(quantile): 순서대로 세개의 점을 first(Q1), second(Q2), third(Q3)
4) 백분위수(percentile): p-percentile, 해당 값 이하의 데이터가 전체의 p%인 값을 의미한다.
first quartile(Q1): 25percentile
second(Q2): 50 percentile-중앙값
third: 75 percentile
산포 측도(scale parameters): 특성값들이 얼마나 멀리/가까이 퍼져있느냐
1) 표본분산(sample variance): 데이터 값이 평균으로 부터 떨어져 있는 정도를 나타내는 값
2) 표본표준편차(sample deviation): 데이터가 얼마나 퍼져있는가를 나타내는 값
3) 평균 절대 편차(mean absolute deviation): 데이터가 얼마나 퍼져있는 가를 나타내는 값
4) 사분위수 범위(interquartile range): IOR, 데이터의 Q3값과 Q1값 차이를 나타내는 값
상관계수(Correlatio Coefficient): 두 변수 간의 선형관계 (꼭, 인과관계를 설명하는 것은 아님)
Pearson, Spearman, Kendall, partial 등
상관계수 해석
1) -1~1까지의 값을 갖는다. (- 음의 상관관계, + 양)
2) 두 변수량 X,Y사이의 선형 관계의 정도를 나타내는 수치
3) 절대값이 0에 가까울 수록 선형관계가 없다.
4) 1에 가까울수록 선형관계가 있다.
Correlation: 두 변수간의 연관성, 선형관계 설명(선/후, 요인과 결과의 여부는 중요하지않음)
Causation: 두 변수간의 연관성, 인과관계의 여부를 중요하게 따짐
왜도(Skewness): 중심을 기준으로 한쪽으로 치우친 정도

출처:https://ko.wikipedia.org/wiki/%EB%B9%84%EB%8C%80%EC%B9%AD%EB%8F%84
1) 왜도=0: 좌우 대칭
2) 왜도>0: 우측 긴 꼬리(positive skew)
3) 왜도<0: 좌측 긴 꼬리(negative skew)
4) 활용: 데이터 분포 형태에 따른 차별화된 방법론 적용/ 정규분포 여부 판단이 가능하다.
첨도(Kurtosis): 분포 형태의 정점위치에서 뾰족한 정도
1) 첨도=0: 정상분포(표준 정규분포와 뾰족한 정도가 같다)
2) 첨도>0: (첨용: Leptokurtic)표준 정규분포보다 뾰족
3) 첨도<0: (평용: platykurtic) 표준 정규분포보다 납작
4) 활용: 정규분포 여부 판단 기능
기술통계(Descriptive Statistics)
기술통계
분석에 앞서 데이터에 대한 대략적인 이해와 분석에 대한 통찰력 얻기
자료 시각화(Visualization)
특징이나 분포를 한눈에 보기
1) 히스토그램(Histogram)
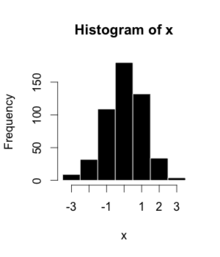
출처:https://ko.wikipedia.org/wiki/%ED%9E%88%EC%8A%A4%ED%86%A0%EA%B7%B8%EB%9E%A8
- 빈도수를 나타내는 그래프
- 사각형의 높이는 구간의 밀도와 동일(구간의폭/빈도수)
- 히스토그램의 전체영역은 데이터의 개수와 동일
- 표준화된 상대도수 표현 가능
- 종류: 빈도/누적/확률분포 히스토그램
- 활용: 연속형 자료의 확률 분포함수의 모양을 파악할 수 있다.
2) 상자그림(box plot): 분포형태 확인 및 분석에 주요한 변수 도출을 위해 사용
자료의 크기 순서를 나타내는 5가지 순서 통계량(최소값, 제1사분위수, 중앙값, 제3사분위수, 최대값)을 이용하여 자료 요약

출처:https://ko.wikipedia.org/wiki/%EC%83%81%EC%9E%90_%EC%88%98%EC%97%BC_%EA%B7%B8%EB%A6%BC
- 자료의 퍼짐이 극도로 큰 이상치를 표현해주면서, 이상치를 제외한 최대값을 알려줌
- 사분위수를 한 눈에 볼 수 있음
- 데이터 분포의 대칭성 확인
- 좌우대칭: 중위수(중앙값)가 상자의 중심부에 위치
- 비대칭: 중위수가 상자의 중심부에 위치 안함
- 이상치와 주요변수를 확인 할 수 있다.
3) 산점도분석
두 변수의 관계를 시각적으로 검토할때 유용, 변수들 사이의 관계를 왜곡시키는 특이점(outlier)을 확인할 수 있다.
- 자료의 분산 정도
- 변수의 단순히 관계를 나타냄 -> 인과관계는 보장할 수 없음
- 데이터간의 상관관계가 있는지 시각적으로 확인
- 정규분포와는 다른 형태를 가질때,
- 박스콕스 변환
-Generalized Linear Model
'Data > 데이터 분석·통계' 카테고리의 다른 글
| [(빅)데이터 교육] 데이터 분석의 기초 - 통계적 추론 (0) | 2018.06.22 |
|---|---|
| [(빅)데이터 교육] 데이터 분석의 기초 - 확률과 확률분포 (0) | 2018.06.22 |
| [(빅)데이터 분석] 데이터 분석의 이해 - 기계학습의 이해 및 데이터 분석 사례 (0) | 2018.06.20 |
| [(빅)데이터 교육] 데이터 분석의 이해 - 데이터 분석 방법론 (2) (0) | 2018.06.20 |
| [(빅)데이터 교육] 데이터 분석의 이해 - 데이터 분석 방법론 (0) | 2018.06.20 |



